您当前的位置:首页>论文资料>探究ID3分类算法的深度网络爬虫设计方法
内容简介
 算法分析
算法分析数字执本与成用
探究ID3分类算法的深度网络爬虫设计方法
王芳芳
(十瑶广播电视大学教育学院理工部湖北十堰442000)
摘要着网络技术不断的发展,互联网作为海量信息的载体已全面渗遗到经济社会的各个领域,推动看我国向信息化社会发展。授索引季技术正在从以移动互联网为标志的个人需求精准索向以物联网为标志的实体技索发展。本文探讨了一种按照ID3算法分类的深度网络爬虫设计方法,该方法按照ID3算法对页面进行收集、分析、处理和分类,从而提取深度表单数据,能够使提索引擎减少提索盲区,有效的改善和优化投索结果。
关键词:ID3算法深度网络爬虫算法中图分类号:TP393
文献标识码:A
文章编号:1007-9416(2015)03-0114-01
1引言
随着互联网的飞速发展,信息的产生量以爆炸式的速度增长,互联网已经成为大量信息的载体,如何有效地提取并利用这些信息成为一个巨大的挑战。经过大量的研究表明,目前互联网上存在着很多网页是不能够通过超级链接的设置面进行访问的。有很多深度位置的网页便成为了引擎搜索的盲区,搜索用户必须要使用一些特殊的关键词查询才能够访问到这些深度网页。其主要的原固在于,使用常规的引擎搜索手段不能有效的模仿用户进行各种类型的表单查询,这些页面无法通过收集和索引操作来完成,不能够存在用户的搜索列表中。常规的鹿虫算法主要依靠网页上的超级连接进行网页的查询和下载,这种普通搜索无法对深度网页进行索引以及查询。本文探讨一种按照ID3算法分类的深度网络爬虫设计方法,能够分析网页和表单的具体特征,并且将其分类,以适当的数据形式提
交给服务器,从面挖掘出深度网页。 2传统网络爬虫算法存在的问题
-般来说,搜索弓擎是由索引器、用户界面以及网络爬虫等模心组件构成。然而,网络爬虫的设计方法是搜索引擎的核心技术。网络爬虫的功能是搜寻互联网中的信息,传统的方法是从一组连接地址开始,使用爬虫算法利用宽度和深度追历的方式搜索以及下载网页信息。当今互联网中信息量呈现爆炸式增长,因此,爬虫算法会漏检很多信息,这就导致网络爬虫的低信息覆盖率的问题,最终导致很多有价值的网页无法被搜索到。原固如:
(1)互联网规模不断的扩大,每天产生大量的信息,由此不断的产生新的网页,面临海量的新生成的网页,网络爬虫的耗费的时间代价过高,固此无法达到很高的网页搜索覆盖率。
(2)传统的网络爬虫算法只能通过超级连接来发现并搜索网页,
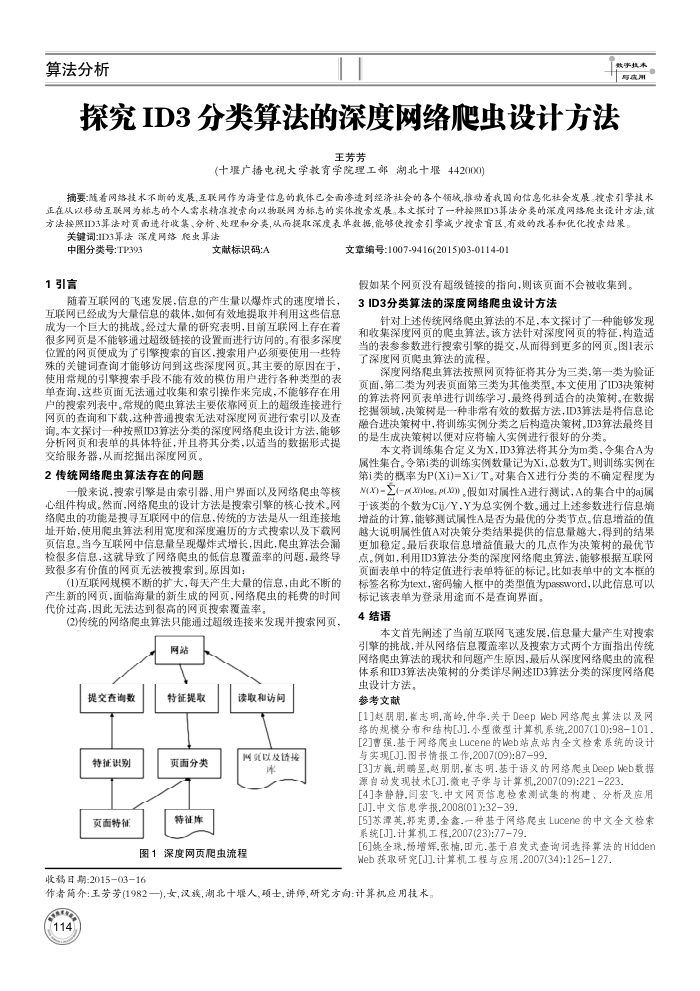
网站
提交查询数特征识别页面特征
特征提取更面分类特征库
读取和访间两资以及读控
图1深度网页爬虫流程
收移日期:2015-03-16
假如某个网页没有超级链接的指向,则该页面不会被收集到。 3ID3分类算法的深度网络爬虫设计方法
针对上述传统网络爬虫算法的不足,本文探讨了一种能够发现和收集深度网页的爬虫算法。该方法针对深度网页的特征,构造适当的表参参数进行搜索引擎的提交,从而得到更多的网页。图1表示了深度网页虫算法的流程。
深度网络爬虫算法按照网页特征将其分为三类,第一类为验证页面,第二类为列表页面第三类为其他类型。本文使用了ID3决策树的算法将网页表单进行训练学习,最终得到适合的决策树。在数据挖据领域,决策树是一种非常有效的数据方法,ID3算法是将信息论融合进决策树中,将训练实例分类之后构造决策树ID3算法最终目的是生成决策树以使对应将输人实例进行很好的分类
本文将训练集合定义为X,ID3算法将其分为m类,令集合A为属性集合。令第类的训练实例数量记为Xi,总数为T。则训练实例在第i类的概率为P(Xi)=Xi/T。对集合X进行分类的不确定程度为 N(X)-之(-^xxi)log:p()。假如对属性A进行测试,A的集合中的aj属于该类的个数为Ci/Y,Y为总实例个数。通过上述参数进行信息摘增益的计算,能够测试属性A是否为最优的分类节点。信息增益的值越大说明属性值A对决策分类结果提供的信息量越大,得到的结果更加稳定。最后获取信息增益值最大的几点作为决策树的最优节点。例如,利用ID3算法分类的深度网络虫算法,能够根据互联网页面表单中的特定值进行表单特征的标记。比如表单中的文本框的标签名称为text,密码输人框中的类型值为password,以此信息可以
标记该表单为登录用途而不是查询界面。 4结语
本文首先阐述了当前互联网飞速发展,信息量大量产生对搜索引擎的挑战,并从网络信息覆盖率以及搜索方式两个方面指出传统网络爬虫算法的现状和问题产生原因,最后从深度网络爬虫的流程体系和ID3算法决策树的分类详尽阐述ID3算法分类的深度网络爬
虫设计方法。参考文献
[1]越朋朋.崔志明.高岭.伸华.关于Deepeb网络展虫算法以及网络的规模分市和结构[J1.小型微型计算机系统.2007(10):98-101[2]曹强.基于网络虑虫Lucene的Web站点站内全文检索系统的设计与实现[J].图书情报工作,2007(09):87-99.
[3]方巍.胡聘显,赵朋朋.崔志明.基于语文的网络爬虫Deepweb数据源自动发现技术[J].微电子学与计算机,2007(09):221-223
[4]李静静.闫宏飞.中文网页临息检索测试集的构建、分析及应用[J].中文情.息学报,2008(01):32-39
[5]苏潭英,郭宪勇.金鑫.一种基于网络爬虫Lucene的中文全文检索系统[J].计算机工程,2007(23):77-79
[6]姚全珠,杨增辉.张楠,田元.基于启发式查询词选择算法的Hidden Web获取研究[J].计算机工程与应用.2007(34):125-127,
作者简介:王芳芳(1982一),女,汉族,湖北十瑶人,项士,讲师,研究方向:计算机应用技术。 14
上一章:OTN 网络频率同步技术探讨
下一章:探析IPRAN网络部署分析及其工程应用